3. Understanding Data
3.1. VTK data model
To use ParaView effectively, you need to understand the ParaView data model. ParaView uses VTK, the Visualization Toolkit, to provide the visualization and data processing model. This chapter briefly introduces the VTK data model used by ParaView. For more details, refer to one of the VTK books [SML06] [KInc10].
The most fundamental data structure in VTK is a data object. Data objects can either be scientific datasets, such as rectilinear grids or finite elements meshes (see below), or more abstract data structures, such as graphs or trees. These datasets are formed from smaller building blocks: mesh (topology and geometry) and attributes.
3.1.1. Mesh
Even though the actual data structure used to store the mesh in memory depends on the type of the dataset, some abstractions are common to all types. In general, a mesh consists of vertices (points ) and cells (elements, zones). Cells are used to discretize a region and can have various types such as tetrahedra, hexahedra, etc. Each cell contains a set of vertices. The mapping from cells to vertices is called the connectivity. Note that even though it is possible to define data elements such as faces and edges, VTK does not represent these explicitly. Rather, they are implied by a cell’s type and by its connectivity. One exception to this rule is the arbitrary polyhedron, which explicitly stores its faces. Fig. 3.1 is an example mesh that consists of two cells. The first cell is defined by vertices \((0, 1, 3, 4)\), and the second cell is defined by vertices \((1, 2, 4, 5)\). These cells are neighbors because they share the edge defined by the points \((1, 4)\).
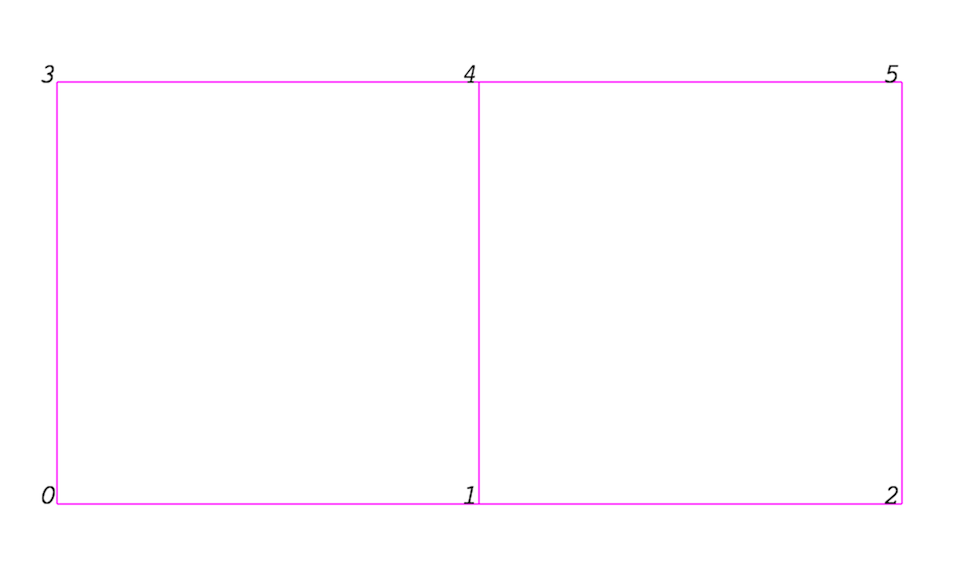
Fig. 3.1 Example of a mesh.
A mesh is fully defined by its topology and the spatial coordinates of its vertices. In VTK, the point coordinates may be implicit, or they may be explicitly defined by a data array of dimensions \((number\_of\_points \times 3)\).
3.1.2. Attributes (fields, arrays)
An attribute (or a data array or field) defines the discrete values of a field over the mesh. Examples of attributes include pressure, temperature, velocity, and stress tensor. Note that VTK does not specifically define different types of attributes. All attributes are stored as data arrays, which can have an arbitrary number of components. ParaView makes some assumptions in regards to the number of components. For example, a 3-component array is assumed to be an array of vectors. Attributes can be associated with points or cells. It is also possible to have attributes that are not associated with either. Fig. 3.2 demonstrates the use of a point-centered attribute. Note that the attribute is only defined on the vertices. Interpolation is used to obtain the values everywhere else. The interpolation functions used depend on the cell type. See the VTK documentation for details.
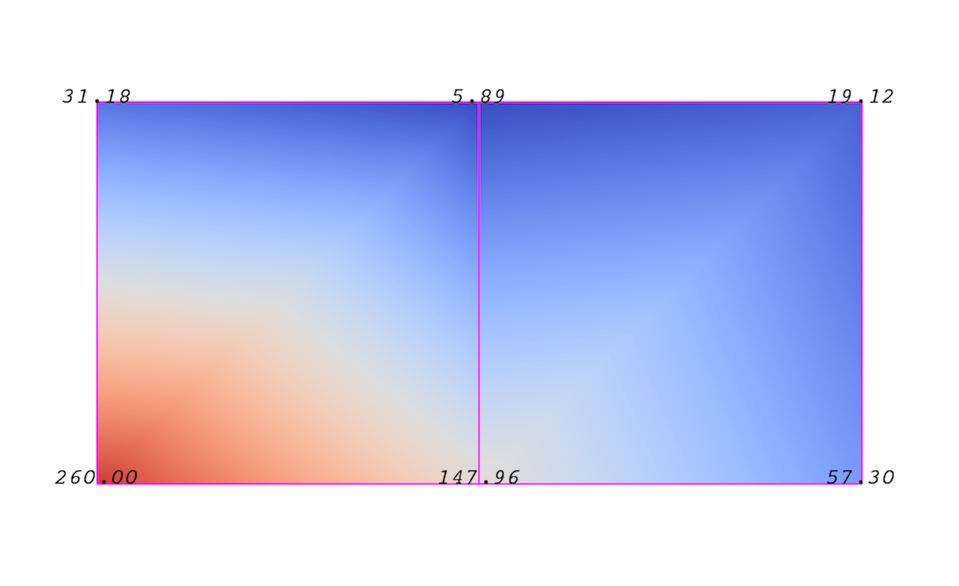
Fig. 3.2 Point-centered attribute in a data array or field.
Fig. 3.3 demonstrates the use of a cell-centered
attribute. Note that cell-centered attributes are assumed to be constant over
each cell. Due to this property, many filters in VTK cannot be directly applied
to cell-centered attributes. It is normally required to apply a Cell Data to
Point Data filter. In ParaView, this filter is applied automatically, when
necessary.
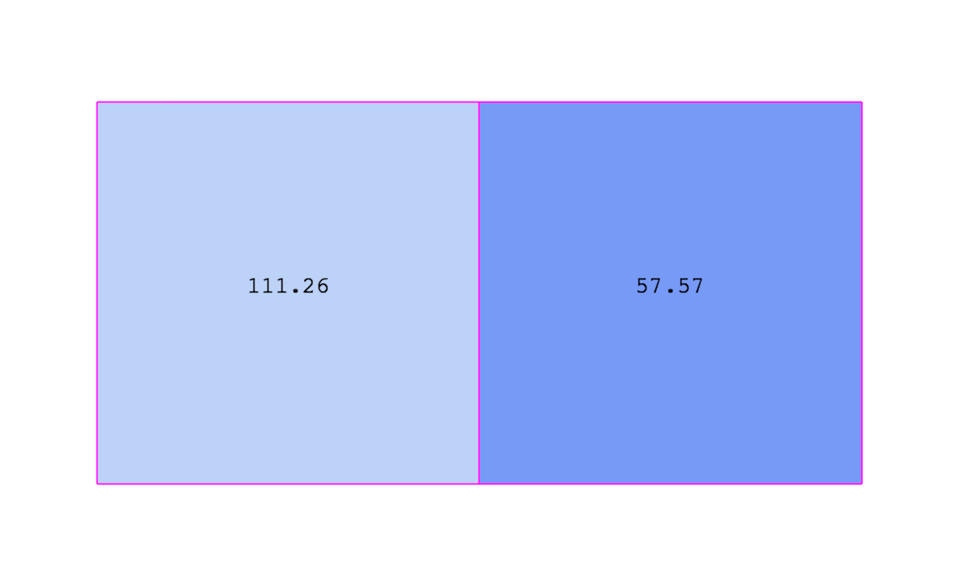
Fig. 3.3 Cell-centered attribute.
3.1.3. Uniform rectilinear grid (image data)
Fig. 3.4 Example uniform rectilinear grid.
A uniform rectilinear grid, or image data, defines its topology and point coordinates implicitly (Fig. 3.4). To fully define the mesh for an image data, VTK uses the following:
Extents - These define the minimum and maximum indices in each direction. For example, an image data of extents \((0, 9)\), \((0, 19)\), \((0, 29)\) has 10 points in the x-direction, 20 points in the y-direction, and 30 points in the z-direction. The total number of points is \(10 \times 20 \times 30\).
Origin - This is the position of a point defined with indices \((0, 0, 0)\).
Spacing - This is the distance between each point. Spacing for each direction can defined independently.
The coordinate of each point is defined as follows: \(coordinate = origin + index \times spacing\) where \(coordinate\), \(origin\), \(index\), and \(spacing\) are vectors of length 3.
Note that the generic VTK interface for all datasets uses a flat index. The \((i,j,k)\) index can be converted to this flat index as follows: \(idx\_flat = k \times (npts_x \times npts_y) + j \times nptr_x + i\).
A uniform rectilinear grid consists of cells of the same type. This type is determined by the dimensionality of the dataset (based on the extents) and can either be vertex (0D), line (1D), pixel (2D), or voxel (3D).
Due to its regular nature, image data requires less storage than other datasets. Furthermore, many algorithms in VTK have been optimized to take advantage of this property and are more efficient for image data.
3.1.4. Rectilinear grid
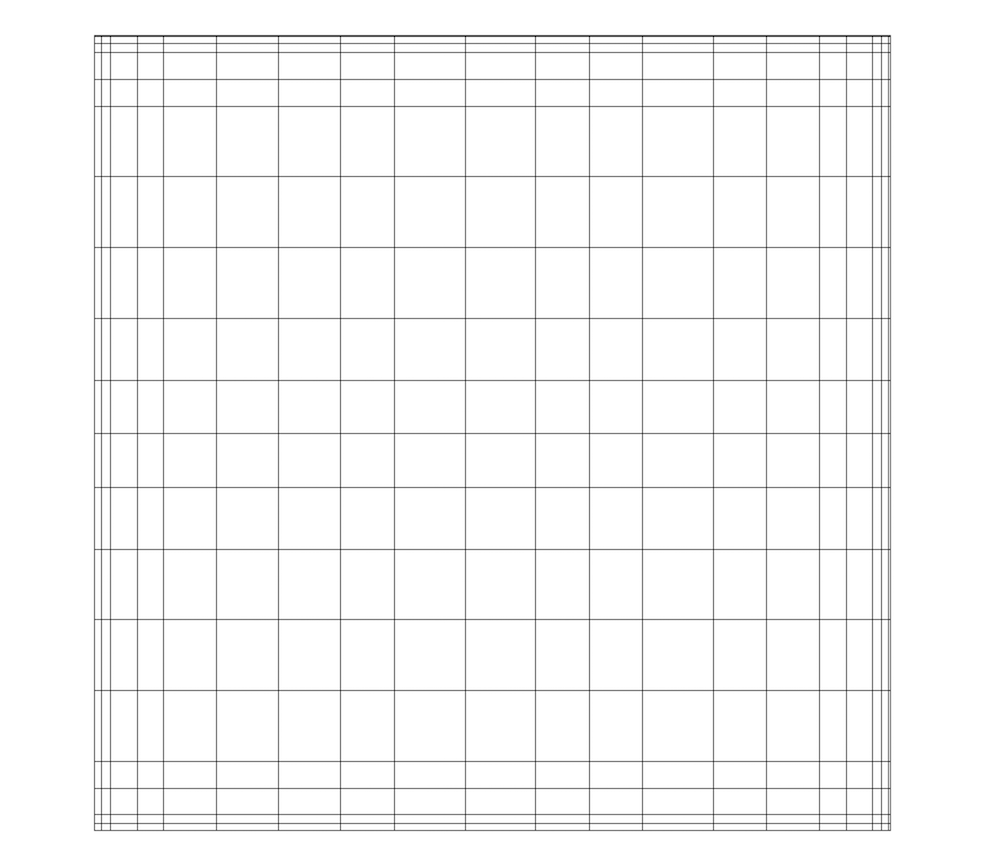
Fig. 3.5 Rectilinear grid.
A rectilinear grid, such as Fig. 3.5, defines its topology implicitly and point coordinates semi-implicitly. To fully define the mesh for a rectilinear grid, VTK uses the following:
Extents - These define the minimum and maximum indices in each direction. For example, a rectilinear grid of extents \((0, 9)\), \((0, 19)\), \((0, 29)\) has 10 points in the x-direction, 20 points in the y-direction, and 30 points in the z-direction. The total number of points is \(10 \times 20 \times 30\).
Three arrays defining coordinates in the x-, y- and z-directions - These arrays are of length \(npts_x\), \(npts_y\), and \(npts_z\). This is a significant savings in memory, as the total memory used by these arrays is \(npts_x+npts_y+npts_z\) rather than \(npts_x \times npts_y \times npts_z\).
The coordinate of each point is defined as follows:
\(coordinate = (coordinate\_array_x(i), coordinate\_array_y(j), coordinate\_array_z(k))\).
Note that the generic VTK interface for all datasets uses a flat index. The \((i,j,k)\) index can be converted to this flat index as follows: \(idx\_flat = k \times (npts_x \times npts_y) + j \times nptr_x + i\).
A rectilinear grid consists of cells of the same type. This type is determined by the dimensionality of the dataset (based on the extents) and can either be vertex (0D), line (1D), pixel (2D), or voxel (3D).
3.1.5. Curvilinear grid (structured grid)
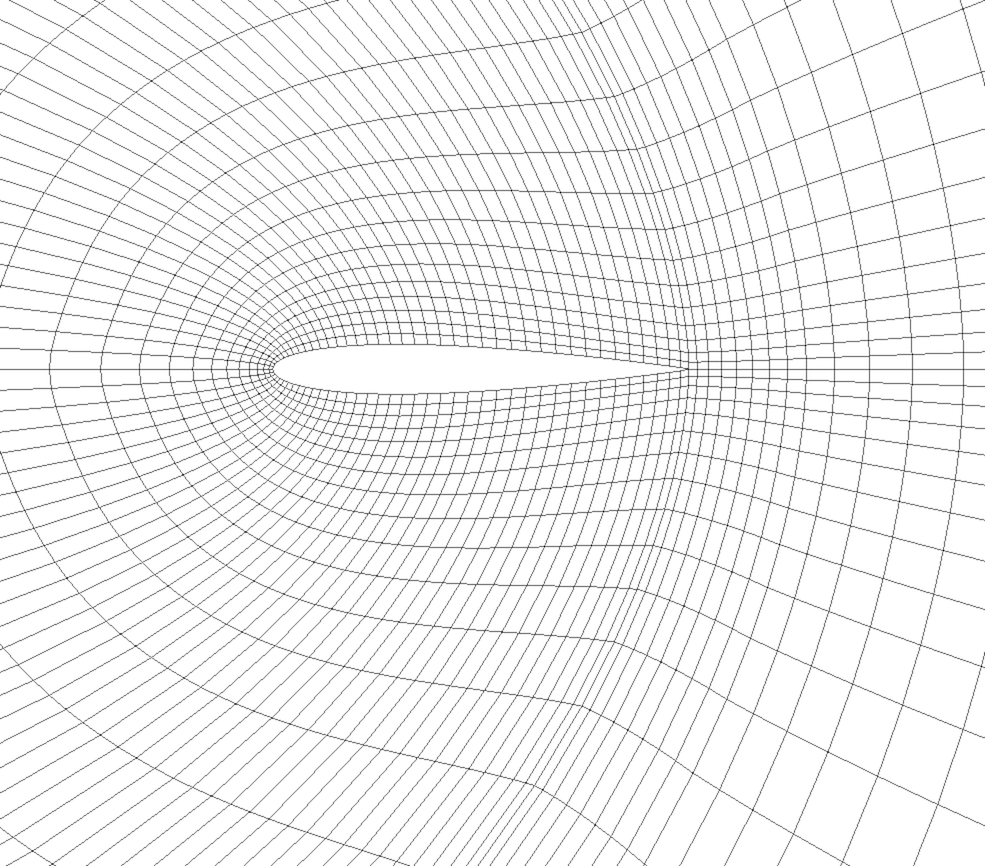
Fig. 3.6 Curvilinear or structured grid.
A curvilinear grid, such as Fig. 3.6, defines its topology implicitly and point coordinates explicitly. To fully define the mesh for a curvilinear grid, VTK uses the following:
Extents - These define the minimum and maximum indices in each direction. For example, a curvilinear grid of extents \((0, 9)\), \((0, 19)\), \((0, 29)\) has \(10 \times 20 \times 30\) points regularly defined over a curvilinear mesh.
An array of point coordinates - This array stores the position of each vertex explicitly.
The coordinate of each point is defined as follows: \(coordinate = coordinate\_array(idx\_flat)\). The \((i,j,k)\) index can be converted to this flat index as follows: \(idx\_flat = k \times (npts_x \times npts_y) + j \times npts_x + i\).
A curvilinear grid consists of cells of the same type. This type is determined by the dimensionality of the dataset (based on the extents) and can either be vertex (0D), line (1D), quad (2D), or hexahedron (3D).
3.1.6. AMR dataset
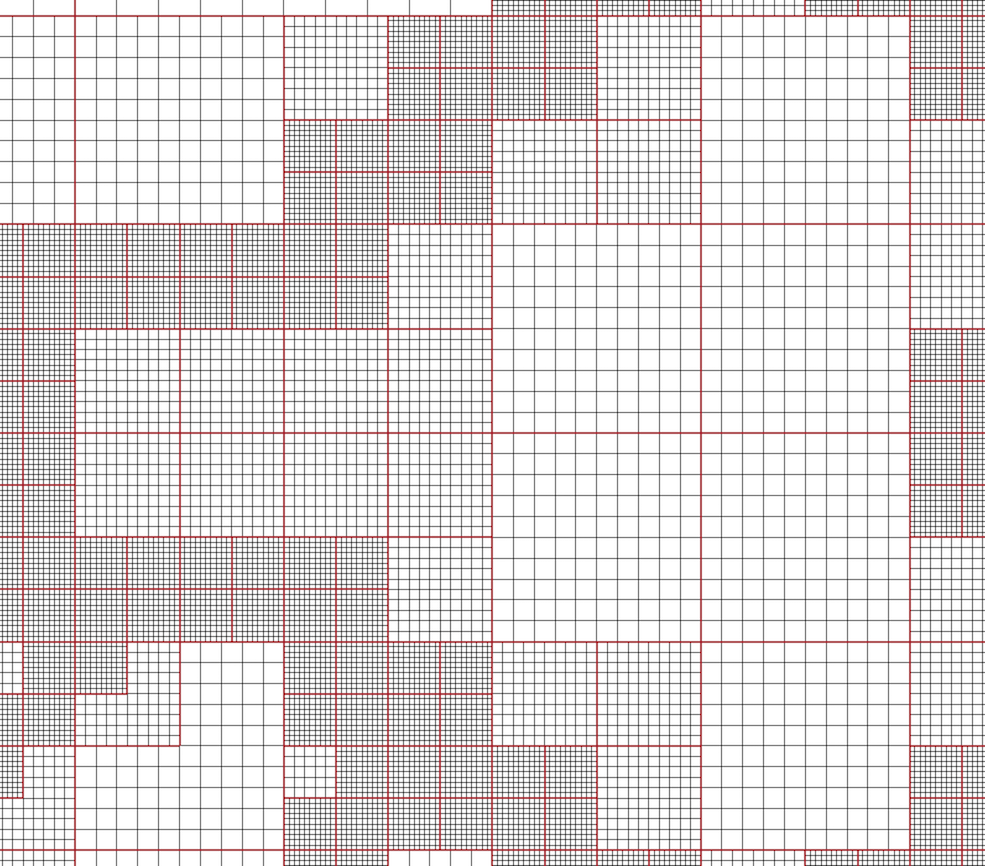
Fig. 3.7 AMR dataset.
VTK natively supports Berger-Oliger type AMR datasets, as shown in Fig. 3.7. An AMR dataset is essentially a collection of uniform rectilinear grids grouped under increasing refinement ratios (decreasing spacing). VTK’s AMR dataset does not force any constraint on whether and how these grids should overlap. However, it provides support for masking (blanking) sub-regions of the rectilinear grids using an array of bytes. This allows VTK to process overlapping grids with minimal artifacts. VTK can automatically generate the masking arrays for Berger-Oliger compliant meshes.
3.1.7. Unstructured grid
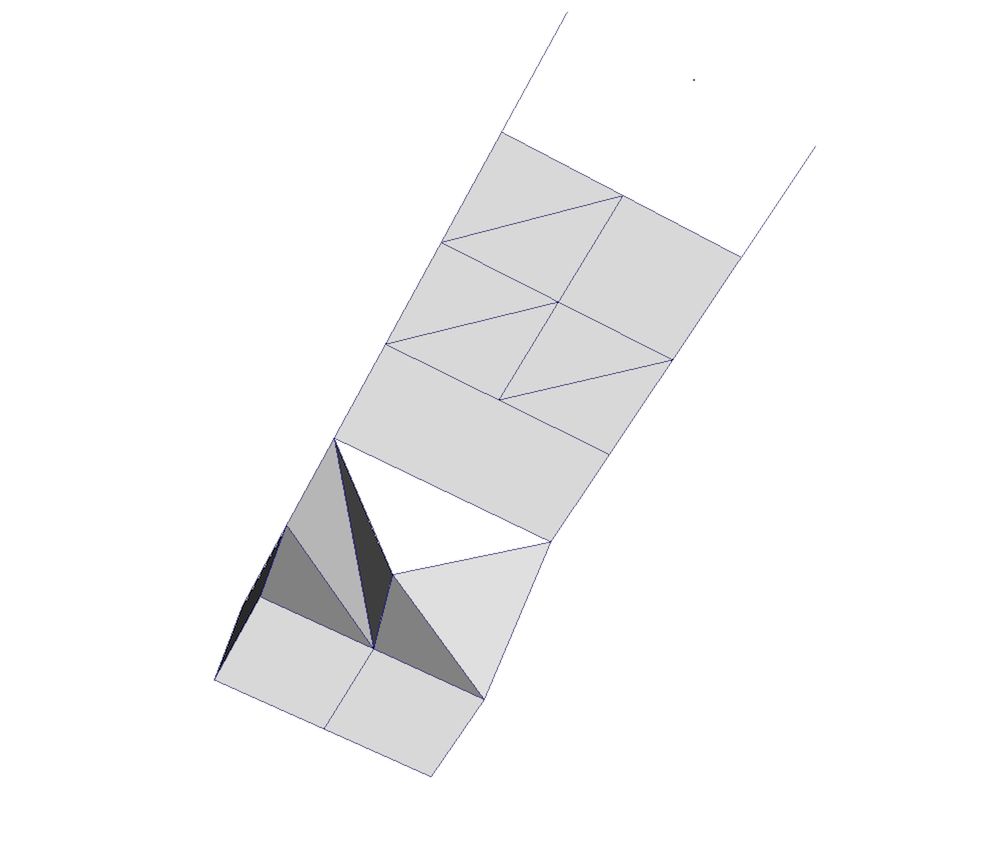
Fig. 3.8 Unstructured grid.
An unstructured grid, such as Fig. 3.8, is the most
general primitive dataset type. It stores topology and point coordinates
explicitly. Even though VTK uses a memory-efficient data structure to store the
topology, an unstructured grid uses significantly more memory to represent its
mesh. Therefore, use an unstructured grid only when you cannot represent your
dataset as one of the above datasets. VTK supports a large number of cell types,
all of which can exist within one heterogeneous unstructured grid. The full
list of all cell types supported by VTK can be found in the file vtkCellType.h
in the VTK source code. Here is the list of cell types as of when this document was written:
VTK_EMPTY_CELL |
VTK_BIQUADRATIC_TRIANGLE |
VTK_VERTEX |
VTK_CUBIC_LINE |
VTK_POLY_VERTEX |
VTK_CONVEX_POINT_SET |
VTK_LINE |
VTK_POLYHEDRON |
VTK_POLY_LINE |
VTK_PARAMETRIC_CURVE |
VTK_TRIANGLE |
VTK_PARAMETRIC_SURFACE |
VTK_TRIANGLE_STRIP |
VTK_PARAMETRIC_TRI_SURFACE |
VTK_POLYGON |
VTK_PARAMETRIC_QUAD_SURFACE |
VTK_PIXEL |
VTK_PARAMETRIC_TETRA_REGION |
VTK_QUAD |
VTK_PARAMETRIC_HEX_REGION |
VTK_TETRA |
VTK_HIGHER_ORDER_EDGE |
VTK_VOXEL |
VTK_HIGHER_ORDER_TRIANGLE |
VTK_HEXAHEDRON |
VTK_HIGHER_ORDER_QUAD |
VTK_WEDGE |
VTK_HIGHER_ORDER_POLYGON |
VTK_PYRAMID |
VTK_HIGHER_ORDER_TETRAHEDRON |
VTK_PENTAGONAL_PRISM |
VTK_HIGHER_ORDER_WEDGE |
VTK_HEXAGONAL_PRISM |
VTK_HIGHER_ORDER_PYRAMID |
VTK_QUADRATIC_EDGE |
VTK_HIGHER_ORDER_HEXAHEDRON |
VTK_QUADRATIC_TRIANGLE |
VTK_LAGRANGE_CURVE |
VTK_QUADRATIC_QUAD |
VTK_LAGRANGE_TRIANGLE |
VTK_QUADRATIC_POLYGON |
VTK_LAGRANGE_QUADRILATERAL |
VTK_QUADRATIC_TETRA |
VTK_LAGRANGE_TETRAHEDRON |
VTK_QUADRATIC_HEXAHEDRON |
VTK_LAGRANGE_HEXAHEDRON |
VTK_QUADRATIC_WEDGE |
VTK_LAGRANGE_WEDGE |
VTK_QUADRATIC_PYRAMID |
VTK_LAGRANGE_PYRAMID |
VTK_BIQUADRATIC_QUAD |
VTK_BEZIER_CURVE |
VTK_TRIQUADRATIC_HEXAHEDRON |
VTK_BEZIER_TRIANGLE |
VTK_TRIQUADRATIC_PYRAMID |
VTK_BEZIER_QUADRILATERAL |
VTK_QUADRATIC_LINEAR_QUAD |
VTK_BEZIER_TETRAHEDRON |
VTK_QUADRATIC_LINEAR_WEDGE |
VTK_BEZIER_HEXAHEDRON |
VTK_BIQUADRATIC_QUADRATIC_WEDGE |
VTK_BEZIER_WEDGE |
VTK_BIQUADRATIC_QUADRATIC_HEXAHEDRON |
VTK_BEZIER_PYRAMID |
Many of these cell types are straightforward. For details, see the VTK documentation.
3.1.8. Polygonal grid (polydata)

Fig. 3.9 Polygonal grid.
A polydata, such as Fig. 3.9, is a specialized version of an
unstructured grid designed for efficient rendering. It consists of 0D cells
(vertices and polyvertices), 1D cells (lines and polylines), and 2D cells
(polygons and triangle strips). Certain filters that generate only these cell
types will generate a polydata. Examples include the Contour and Slice filters.
An unstructured grid, as long as it has only 2D cells supported by polydata, can
be converted to a polydata using the Extract Surface Filter . A polydata can be
converted to an unstructured grid using Clean to Grid .
3.1.9. Table
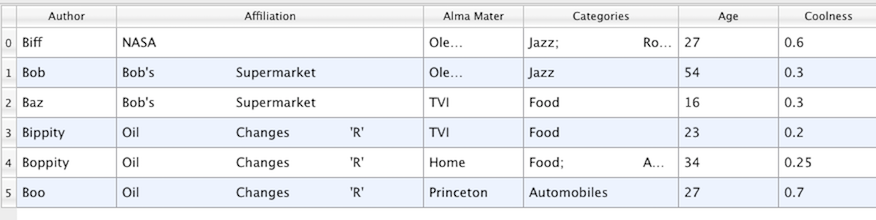
Fig. 3.10 Table
A table, such as Fig. 3.10, is a tabular dataset that consists of rows
and columns. All chart views have been designed to work with tables. Therefore,
all filters that can be shown within the chart views generate tables. Also,
tables can be directly loaded using various file formats such as the comma-separated
values format. Tables can be converted to other datasets as long as
they are of the right format. Filters that convert tables include Table to
Points and Table to Structured Grid .
3.1.10. Multiblock dataset

Fig. 3.11 Multiblock dataset.
You can think of a multiblock dataset (Fig. 3.11) as a
tree of datasets where the leaf nodes are simple datasets. All of the
data types described above, except AMR, are simple datasets. Multiblock
datasets are used to group together datasets that are related. The relation
between these datasets is not necessarily defined by ParaView. A multiblock
dataset can represent an assembly of parts or a collection of meshes of
different types from a coupled simulation. Multiblock datasets can be loaded or
created within ParaView using the Group filter. Note that the leaf nodes of a
multiblock dataset do not all have to have the same attributes. We call attributes
that are not present on all blocks of a multiblock dataset partial attributes
or partial arrays If you apply a filter that requires an attribute, it will be
applied only to blocks that have that attribute.
3.1.11. Multipiece dataset

Fig. 3.12 Multipiece dataset.
Multipiece datasets, such as Fig. 3.12, are similar to multiblock datasets in that they group together simple datasets. There is one key difference. Multipiece datasets group together datasets that are part of a whole mesh - datasets of the same type and with the same attributes. This data structure is used to collect datasets produced by a parallel simulation without having to append the meshes together. Note that there is no way to create a multipiece dataset within ParaView. It can only be created by using certain readers. Furthermore, multipiece datasets act, for the most part, as simple datasets. For example, it is not possible to extract individual pieces or to obtain information about them.
3.2. Getting data information in paraview
In the visualization pipeline (Section 1.2),
sources, readers, and filters are all producing data. In a VTK-based pipeline,
this data is one of the types discussed. Thus, when you create a source or open
a data file in paraview and hit Apply , data is being produced.
The Information panel and the Statistics Inspector panel can be used
to inspect the characteristics of the data produced by any pipeline module.
3.2.1. The Information panel
The Information panel provides summary information about the data produced by
the active source. By default, this panel is tucked under a tab below the
Properties panel. You can toggle its visibility using View > Information.
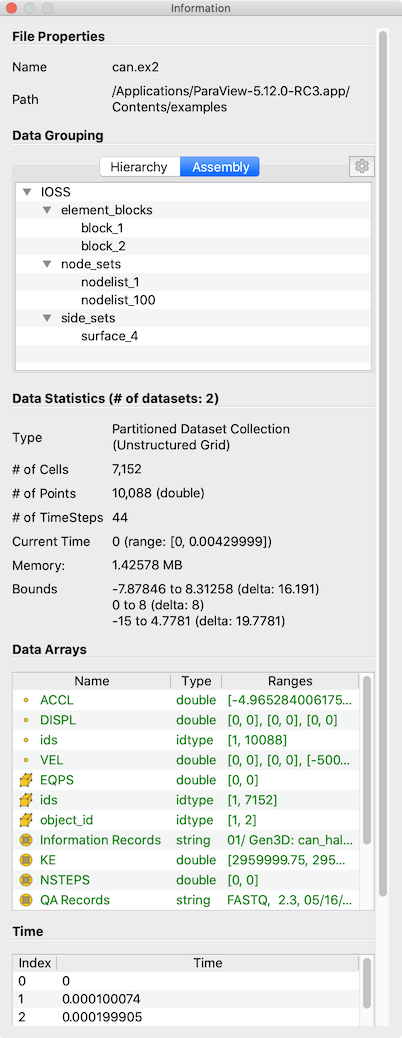
Fig. 3.13 The Information panel in paraview showing data summaries for the active source.
The Information panel shows the data information for the active source. Thus,
similar to the Properties panel, it changes when the active source is
changed (e.g., by changing the selection in the Pipeline Browser ). One way
to think of this panel is as a panel showing a summary for the data currently
produced by the active source. Remember that a newly-created pipeline
module does not produce any data until you hit Apply . Thus, valid
information for a newly-created source will be shown on this panel only after
that Apply . Similarly, if you change properties on the source and hit
Apply , this panel will
reflect any changes in data characteristics. Additionally, for temporal pipelines, this panel shows
information for the current timestep alone (except as noted). Thus, as you step
through timesteps in a temporal dataset, the information displayed
will potentially change, and the panel will reflect those changes.
Did you know?
Any text on this panel is copy-able. For example, if want to copy the
number of points value to use it as a property value on the Properties
panel, simply double-click on the number or click-and-drag to select the
number and use the common keyboard shortcut CTRL + C (or
⌘ + C) to copy that value to the clipboard. Now, you can paste it
in an input widget in paraview or any other application, such as an
editor, by using CTRL + V (or ⌘ + V) or the application-specific
shortcut for pasting text from the clipboard. The same is true for numbers shown in
lists, such as the Data Ranges .
The several groups of information comprise the panel itself. Groups may be hidden based on the type of pipeline module or the type of data being produced.
The file File Properties group is shown for readers with information about the
file that is opened. For a temporal file series, as you step through each
time step, the file name is updated to point to the name of the file in the
series that corresponds to the current time step.
The Data Grouping section shows information about composite datasets consisting of
more than one datasets in some kind of hierarchical arrangement. Two different hierarchies
are available. The Hierarchy shows the relationships of datasets inherent
in the composite dataset structure, while the Assembly shows relationships among
datasets that are explicity defined by the data source.
The Data Statistics group provides a summary of the dataset produced including its
type, its number of cells and points (or rows and columns in cases of Tabular
datasets), the number of timesteps, the current time, and an estimate of the memory used by the
dataset. This number only includes the memory space needed to save the data arrays for the dataset.
It does not include the memory space used by the data structures themselves and, hence, must only
be treated as an estimate. Lastly, the group shows the spatial bounds of the datasets in 3D Cartesian
space. This will be unavailable for non-geometric datasets such as tables.
The Data Arrays group lists all of the available point, cells, and field arrays,
as well as their types and ranges for the current time step. The Current Time
field shows the time value for the current timestep as a reference. As with
other places in paraview, the icons  ,
,  , and
, and  are used
to indicate cell, point, and field data arrays. Since data arrays can have multiple
components, the range for each component of the data array is shown.
are used
to indicate cell, point, and field data arrays. Since data arrays can have multiple
components, the range for each component of the data array is shown.
For reader modules, the Time group shows the available time steps and corresponding
time values provided by the file.
For structured datasets such as uniform rectilinear grids or curvilinear grids,
the Extents group is shown that displays the structured extents and dimensions
of the datasets.
All of the summary information discussed so far provides a synopsis of the entire dataset
produced by the pipeline module, including across all ranks (which will become
clearer once we look at using ParaView for parallel data processing). In cases
of composite datasets, such as mutliblock datasets or AMR datasets, recall that
these are datasets that are made up of other datasets. In such cases, these
are summaries over all the blocks in the composite dataset. Every so often,
you will notice that the Data Arrays table lists an array with the suffix
(partial) (Figure Fig. 3.14).
Such arrays are referred to as partial arrays. Partial arrays
is a term used to refer to arrays that are present on some non-composite
blocks or leaf nodes in a composite dataset, but not all. The (partial)
suffix to indicate partial arrays is also used by paraview in other
places in the UI.

Fig. 3.14 The Data Arrays section on Information panel showing partial arrays. Partial arrays are arrays that present on certain blocks in a composite dataset, but not all.
While summaries over all of the datasets in the composite dataset are useful,
you may also want to look at the data information for individual blocks.
To do so, you can use the Data Hierarchy group, which appears when
summarizing composite datasets. The Data Hierarchy widget shows the
structure or hierarchy of the composite dataset
(Figure Fig. 3.15). The Information panel
switches to showing the summaries for the selected sub-tree.
By default, the root element will be selected. You can now select any block in
the hierarchy to view the summary limited to just that sub-tree.
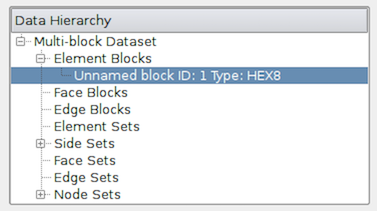
Fig. 3.15 The Data Hierarchy section on the Information panel showing
the composite data hierarchy. Selecting a particular block or subtree in this
widget will result in the reset of the Information panel showing
summaries for that block or subtree alone.
Did you know?
Memory information shown on the Information panel and
the Statistics Inspector
should only be used as an approximate reference and does not translate
to how much memory the data produced by a particular pipeline module takes. This is due
to the following factors:
The size does not include the amount of memory needed to build the data structures to store the data arrays. While, in most cases, this is negligible compared to that of the data arrays, it can be nontrivial, especially when dealing with deeply-nested composite datasets.
Several filters such as
CalculatorandShrinksimply pass input data arrays through, so there’s no extra space needed for those data arrays that are shared with the input. The memory size numbers shown, however, do not take this into consideration.
If you need an overview of how much physical memory is being used by ParaView in
its current state, you can use the Memory Inspector
(Section 8).
3.2.2. The Statistics Inspector panel
The Information panel shows data information for the active source. If you
need a quick summary of the data produced by all the pipeline modules, you can
use the Statistics Inspector panel. It’s accessible from
Views > Statistics Inspector.

Fig. 3.16 The Statistics Inspector panel in paraview showing summaries for all pipeline modules.
All of the information on this panel is also presented on the Information
panel, except Geometry Size . This corresponds to how much memory is
needed for the transformed dataset used for rendering in the active view. For example, to
render a 3D dataset as a surface in the 3D view, ParaView must extract the
surface mesh as a polydata. Geometry Size represents the memory needed for
this polydata with the same memory-size-related caveats as with the
Information panel.
3.3. Getting data information in pvpython
When scripting with ParaView, you will often find yourself needing information
about the data. While paraview sets up filter properties and color
tables automatically using the information from the data, you
must do that explicitly when scripting.
In pvpython, for any pipeline module (sources, readers, or
filters), you can use the following ways to get information about the data
produced.
>>> from paraview.simple import *
>>> reader = OpenDataFile(".../ParaViewData/Data/can.ex2")
# We need to update the pipeline. Otherwise, all of the data
# information we get will be from before the file is actually
# read and, hence, will be empty.
>>> UpdatePipeline()
>>> dataInfo = reader.GetDataInformation()
# To get the number of cells or points in the dataset:
>>> dataInfo.GetNumberOfPoints()
10088
>>> dataInfo.GetNumberOfCells()
7152
# You can always nest the call, e.g.:
>>> reader.GetDataInformation().GetNumberOfPoints()
10088
>>> reader.GetDataInformation().GetNumberOfCells()
7152
# Use source.PointData or source.CellData to get information about
# point data arrays and cell data arrays, respectively.
# Let's print the available point data arrays.
>>> reader.PointData[:]
[Array: ACCL, Array: DISPL, Array: GlobalNodeId, Array: PedigreeNodeId, Array: VEL]
# Similarly, for cell data arrays:
>>> reader.CellData[:]
[Array: EQPS, Array: GlobalElementId, Array: ObjectId, Array: PedigreeElementId]
PointData (and CellData ) is a map or dictionary where the keys are the
names of the arrays, and the values are objects that provide more information
about each of the arrays. In the rest of this section, anything we demonstrate on
PointData is also applicable to CellData .
# Let's get the number of available point arrays.
>>> len(reader.PointData)
5
# Print the names for all available point arrays.
>>> reader.PointData.keys()
['ACCL', 'DISPL', 'GlobalNodeId', 'PedigreeNodeId', 'VEL']
>>> reader.PointData.values()
[Array: ACCL, Array: DISPL, Array: GlobalNodeId, Array: PedigreeNodeId, Array: VEL]
# To test if a particular array is present:
>>> reader.PointData.has_key("ACCL")
True
>>> reader.PointData.has_key("--non-existent-array--")
False
From PointData (or CellData ), you can get access to an object
that provides information for each of the arrays. This object gives us
methods to get data ranges, component counts, tuple counts, etc.
# Let's get information about 'ACCL' array.
>>> arrayInfo = reader.PointData["ACCL"]
>>> arrayInfo.GetName()
'ACCL'
# To get the number of components in each tuple and the number
# of tuples in the data array:
>>> arrayInfo.GetNumberOfTuples()
10088
>>> arrayInfo.GetNumberOfComponents()
3
# Alternative way for doing the same:
>>> reader.PointData["ACCL"].GetNumberOfTuples()
10088
>>> reader.PointData["ACCL"].GetNumberOfComponents()
3
# To get the range for a particular component, e.g. component 0:
>>> reader.PointData["ACCL"].GetRange(0)
(-4.965284006175352e-07, 3.212448973499704e-07)
# To get the range for the magnitude in cases of multi-component arrays
# use -1 as the component number.
>>> reader.PointData["ACCL"].GetRange(-1)
(0.0, 1.3329898584157294e-05)
# To determine the data data type for this array:
>>> from paraview import vtk
>>> reader.PointData["ACCL"].GetDataType() == vtk.VTK_DOUBLE
True
# The paraview.vtk module provides access to these constants such as
# VTK_DOUBLE, VTK_FLOAT, VTK_INT, etc.
# Likewise, to test the dataset type, itself:
>>> reader.GetDataInformation().GetDataSetType() == \
vtk.VTK_MULTIBLOCK_DATA_SET
True
Here’s a sample script to iterate over all point data arrays and print their magnitude ranges:
>>> def print_point_data_ranges(source):
... """Prints array ranges for all point arrays"""
... for arrayInfo in source.PointData:
... # get the array's name
... name = arrayInfo.GetName()
... # get magnitude range
... range = arrayInfo.GetRange(-1)
... print "%s = [%.3f, %.3f]" % (name, range[0], range[1])
# Let's call this function on our reader.
>>> print_point_data_ranges(reader)
ACCL = [0.000, 0.000]
DISPL = [0.000, 0.000]
GlobalNodeId = [1.000, 10088.000]
PedigreeNodeId = [1.000, 10088.000]
VEL = [0.000, 5000.000]
Did you know?
The example scripts in this section all demonstrated how to obtain information about the data such as the number of points and cells, data bounds, and array ranges. However, what they do not show is how to access the raw data itself. To see how to obtain the full data, please see Section 7.11.